Dữ liệu là 1 tệp CSV gồm 3 cột, cột đầu là nhãn, cột 2 và cột 3 là tọa độ X, Y của các điểm trên mặt phẳng. Nếu vẽ đúng, bạn sẽ được hình tương tự như sau. Trong đó điểm đỏ thuộc lớp +1, điểm xanh thuộc lớp -1.
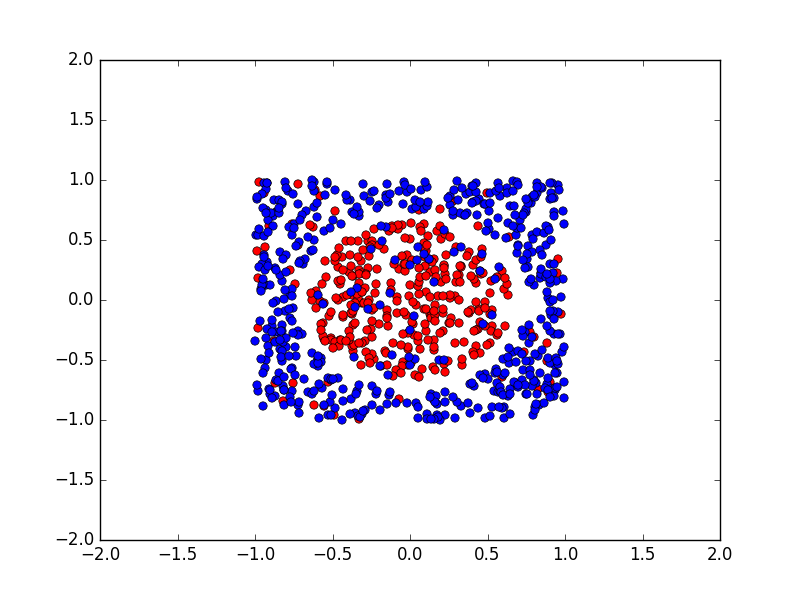
Rõ ràng, nếu chỉ dùng phân lớp tuyến tính đơn thuần, ta không thể nào phân lớp vùng xanh và vùng đỏ trong hình trên. Do đó ta cần tìm cách phi tuyến hóa mô hình. Một trong các cách đó như sau:
Vẽ đường biên quyết định của mô hình bạn tìm được. Nếu làm đúng, bạn sẽ có hình tương tự như sau:
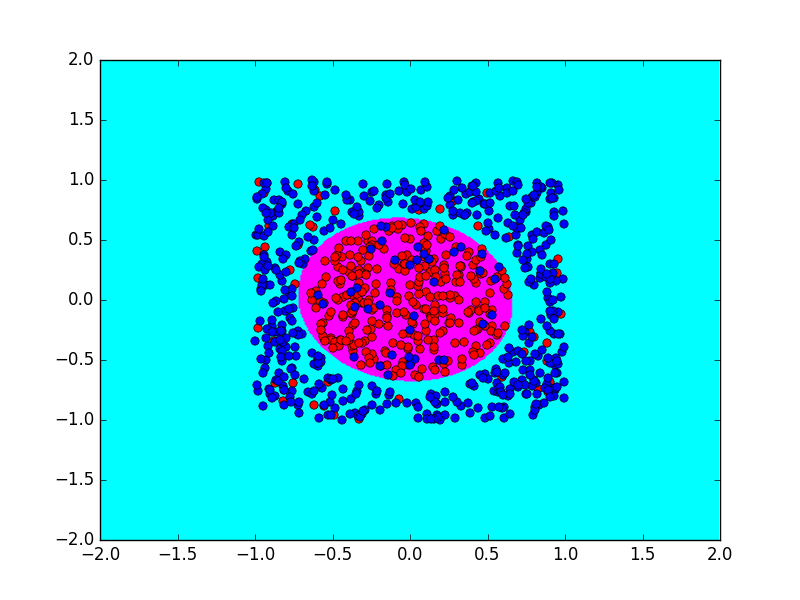
Hãy thay đổi tham số điều chỉnh giảm \(\lambda\) nói ở trên và vẽ biểu đồ số mẫu bị đoán sai như một hàm của \(\lambda\).
Điều gì xảy ra nếu ta sử dụng mô hình bậc 3, tức là sử dụng $$[1,x,y,x^2,xy,y^2,x^3,x^2y,xy^2,y^3]$$ Vẽ biểu đồ các trọng số của mô hình này như các hàm của \(\lambda\).